H264编码分析及隐写实践 目录
CTF竞赛中经常出现图片隐写,视频作为更高量级的信息载体,应当有更大的隐写空间。本文就简单介绍一下H264编码以及一次校赛相关出题经历。
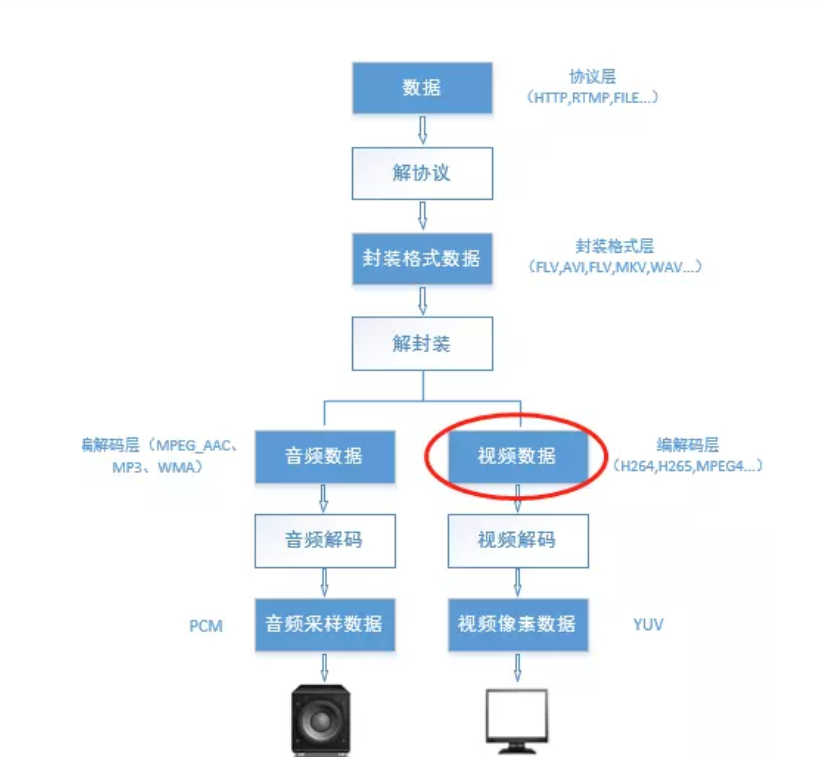
1 视频数据层级 平常我们生活中遇到的大部分是FLV、AVI等等的视频格式,但实际上这只是一种封装,实际的数据还是要看视频的编码,就比如H264。像我们平时在视频网站看到的视频就是通过HTTP协议传输的,直播则是RTMP协议,协议承载的一般是封装后的视频数据。
下图就很好的展示了视频数据的各个层级。
2 H264裸流 得到最原始的视频数据,需要提取H264裸流。
简单介绍一下ffmpeg的用法,不指定格式的情况下,ffmpeg会识别给定文件名的后缀自动进行转换,比如
1 ffmpeg input.flv output.mp4
就会自动转换为mp4
如何提取一个H264编码的视频裸流呢。
使用以下命令。
1 ffmpeg -vcodec copy -i input.flv output.h264
默认不加参数的情况,ffmpeg会把视频重新编码,视频数据会发生变化,所以要加上-vcodec copy,指示ffmpeg直接复制视频流,而不是重新编码。
这样得到的h264裸流就是封装格式中的原始数据。
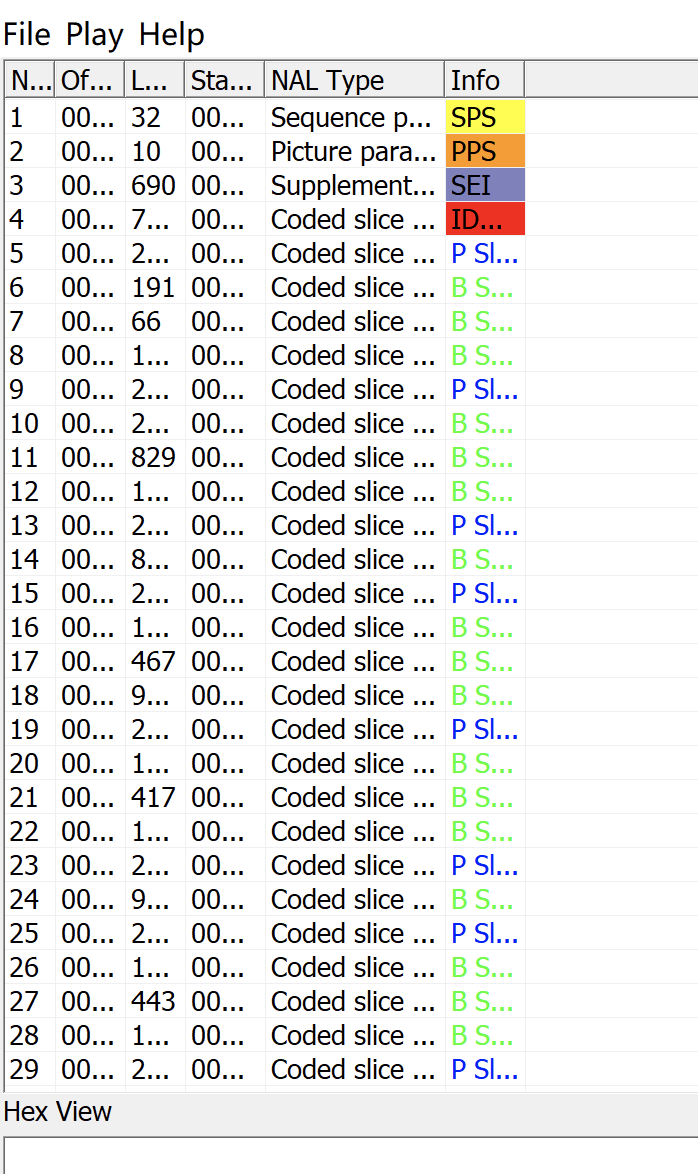
有了H264裸流,可以使用
的工具查看裸流信息。
3 NALU H.264裸流是由⼀个接⼀个NALU组成。H264对NALU的封装有两种方式,一种是AnnexB,一种是 avcC。
这里仅介绍AnnexB,对avcC感兴趣的可以看
。
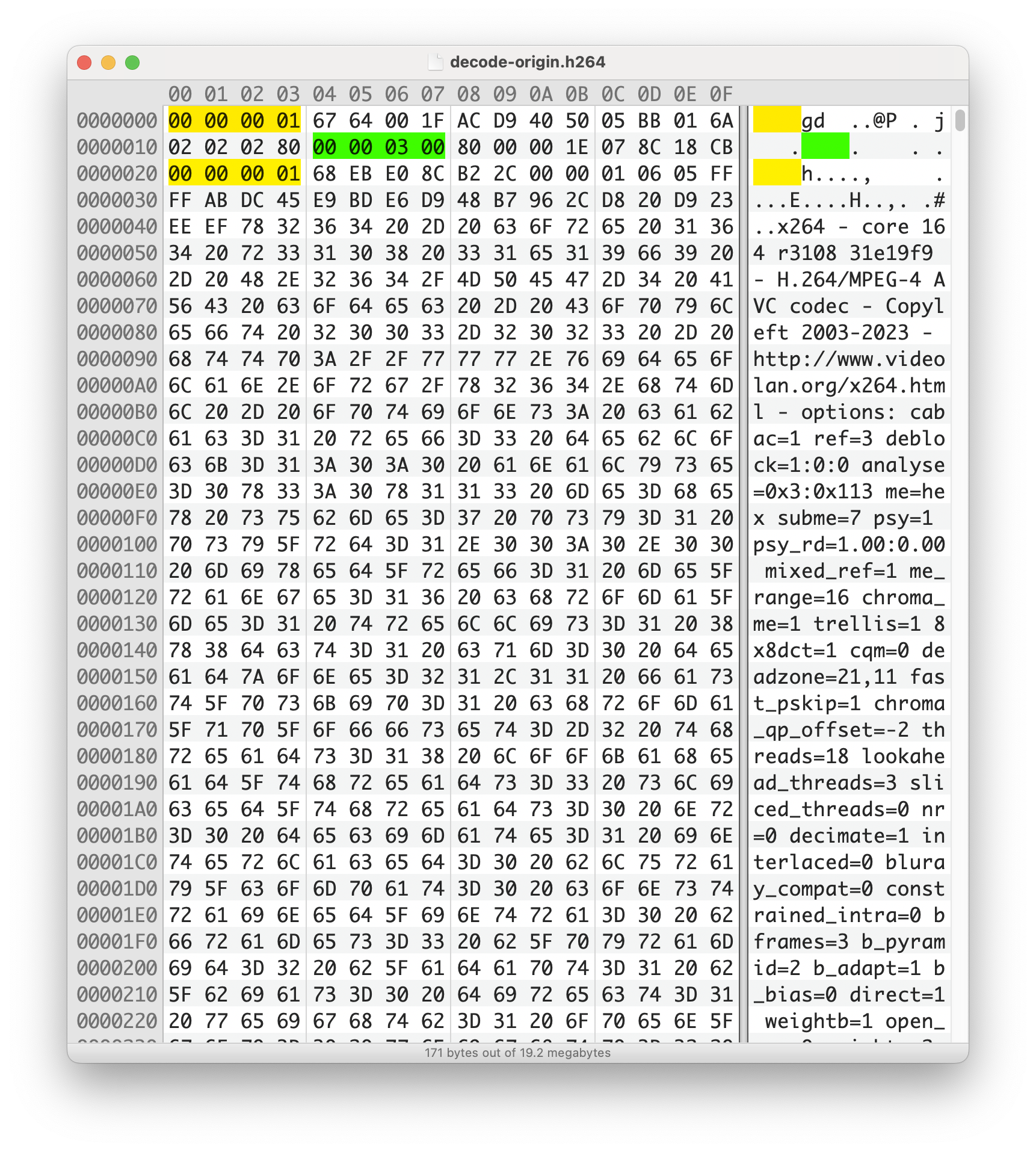
AnnexB的封装很简单,以00 00 00 01或者00 00 01开头作为一个新NALU的标志,为了防止竞争,即 NALU数据中出现00 00 00 01导致解码器误认为是一个新的NALU,所以采用了一些防竞争的策略。
1 2 3 4 00 00 00 => 00 00 03 00 00 00 01 => 00 00 03 01 00 00 02 => 00 00 03 02 00 00 03 => 00 00 03 03
看一眼下面的图就很清楚了。
那么也就是说当我们把数据从H264裸流中提取出来之后,还需要对防竞争字节进行还原。
这里的话对这些类型的数据有些定义,详细可以去看
。
NALU:去除00 00 00 01标志符的数据EBSP:去除NALU header(通常是第一个字节)但未还原防竞争字节的数据RBSP:将EBSP还原防竞争字节后的数据
1 2 3 4 5 6 7 8 一段AnnexB封装的NALU: 00 00 00 01 67 64 00 1F AC D9 40 50 05 BB 01 6A 02 02 02 80 00 00 03 00 80 00 00 1E 07 8C 18 CB NALU: 67 64 00 1F AC D9 40 50 05 BB 01 6A 02 02 02 80 00 00 03 00 80 00 00 1E 07 8C 18 CB EBSP: 64 00 1F AC D9 40 50 05 BB 01 6A 02 02 02 80 00 00 03 00 80 00 00 1E 07 8C 18 CB RBSP: 64 00 1F AC D9 40 50 05 BB 01 6A 02 02 02 80 00 00 00 80 00 00 1E 07 8C 18 CB
4 RBSP 现在有了NALU数据,我们就可以对着
上的内容来一步步解码了。
直接看到手册7.3节,这里是表格式的语法,右边的Descriptor描述了数据的格式及占用的bit数,比如第一个f(1)表示1bit fixed-pattern bit string。
可以在7.2节找到所有的Descriptor定义
还是拿之间的数据做例子
1 2 67 64 00 1F AC D9 40 50 05 BB 01 6A 02 02 02 80 00 00 00 80 00 00 1E 07 8C 18 CB
第一个字节为0b01100111(这部分称为NALU header),那么
1 2 3 4 forbidden_zero_bit= (byte >> 7) & 0x1 = 0 nal_ref_idc = (byte >> 5) & 0x3 = 3 nal_unit_type = byte & 0x1F = 7
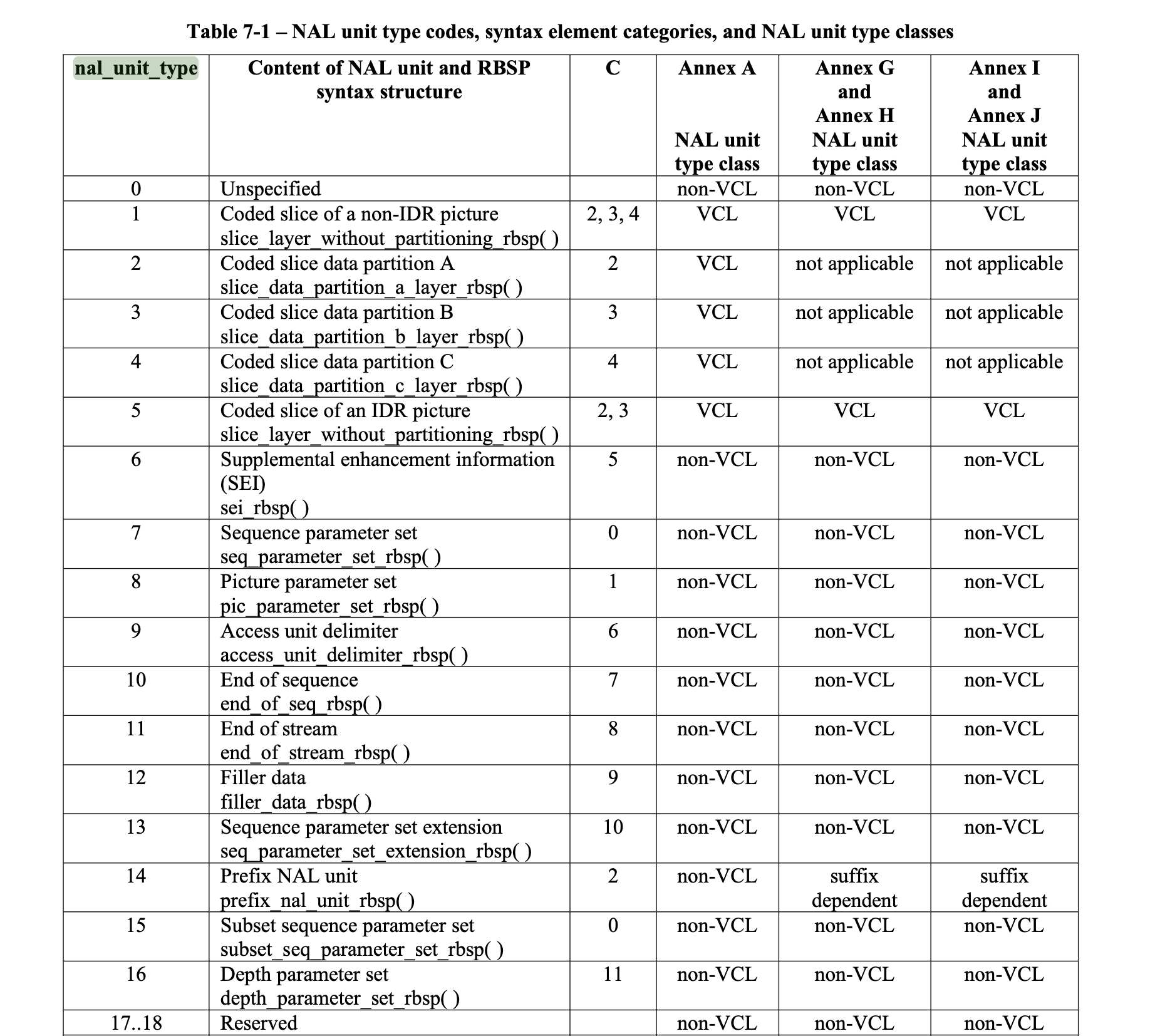
有了nal_unit_type,可以在7.4节的Table 7-1找到对应的类型和对RBSP数据的解析。
4.1 指数哥伦布熵编码 在Descriptor中有以下几种特殊的编码
无符号指数哥伦布熵编码 ue(v)
有符号指数哥伦布熵编码 se(v)
映射指数哥伦布熵编码 me(v)
截断指数哥伦布熵编码 te(v)
这部分建议跟着
来自己复现一下。
5 NALU种类 NALU种类有很多,简单介绍几个重要的
SPS(Sequence Paramater Set):序列参数集, 包括一个图像序列的所有信息,如图像尺寸、视频格式等。
PPS(Picture Paramater Set):图像参数集,包括一个图像的所有分片的所有相关信息,包括图像类型、序列号等。
在传输视频流之前,必须要传输这两类参数,不然无法解码 。为了保证容错性,每一个 I 帧前面,都会传一遍这两个参数集合。
一个流由多个帧序列组成,一个序列由以下三种帧组成。
I帧(Intra-coded picture帧内编码图像帧):不参考其他图像帧,只利⽤本帧的信息进⾏编码。
P帧(Predictive-codedPicture预测编码图像帧):利⽤之前的I帧或P帧,采⽤运动预测的⽅式进⾏帧间预测编码。
B帧(Bidirectionallypredicted picture双向预测编码图像帧):提供最⾼的压缩⽐,它既需要之前的图像帧(I帧或P帧),也需要后来的图像帧(P帧),采⽤运动预测的⽅式进⾏帧间双向预测编码。
这些个帧组成一个序列,每个序列的第一个帧是IDR帧
IDR(Instantaneous Decoding Refresh,即时解码刷新):⼀个序列的第⼀个图像叫做 IDR 图像(⽴即刷新图像),IDR 图像都是 I 帧图像。
IDR帧必须是I帧,但是I帧可以不是IDR帧 。
其他
SEI(Supplemental Enhancement Information辅助增强信息):SEI是H264标准中一个重要的技术,主要起补充和增强的作用。 SEI没有图像数据信息,只是对图像数据信息或者视频流的补充,有些内容可能对解码有帮助.
6 实践 在BUAACTF2024中出了一道H264编码的视频题,思路如下。
首先有一个正常的带flag的视频
希望把视频损坏,但是是可修复的损坏。
首先用ffmpeg重新编码一下,不然太清晰裸流的文件大小很大
1 os.system('ffmpeg -i flag.mp4 -c:v libx264 -crf 18 -preset medium -c:a aac -b:a 128k encode-origin.h264 ' )
并生成一个H264裸流文件,接下来就是对H264裸流进行操作。
python中操作H264裸流可以用
库
1 2 3 4 H26xParser = H26xParser(ORIGIN_H264, verbose=False ) H26xParser.parse() nalu_list = H26xParser.nalu_pos
nalu_pos方法 返回的是一个元组列表,前两个表示的是nalu数据的开始字节和结束字节
然后获取rbsp数据,用getRSBP方法,这个方法返回的数据是包含NALU头部的。
1 2 3 4 5 6 for tu in nalu_list: start, end, _, _, _, _ = tu rbsp = bytes (H26xParser.getRSBP(start, end)) nalu_header = rbsp[0 ] nal_unit_type = nalu_header & 0x1F nalu_body = rbsp[1 :]
6.1 修改IDR帧类型 前面提到,IDR帧的类型必须是I帧 ,所以可以将他的类型进行改变。改变IDR帧的帧类型
1 2 if nal_unit_type == 5 : origin_data[start + 1 ] = origin_data[start + 1 ] | 0x4
nal_unit_type == 5意味着这是一个IDR帧,然后看IDR的解析语法
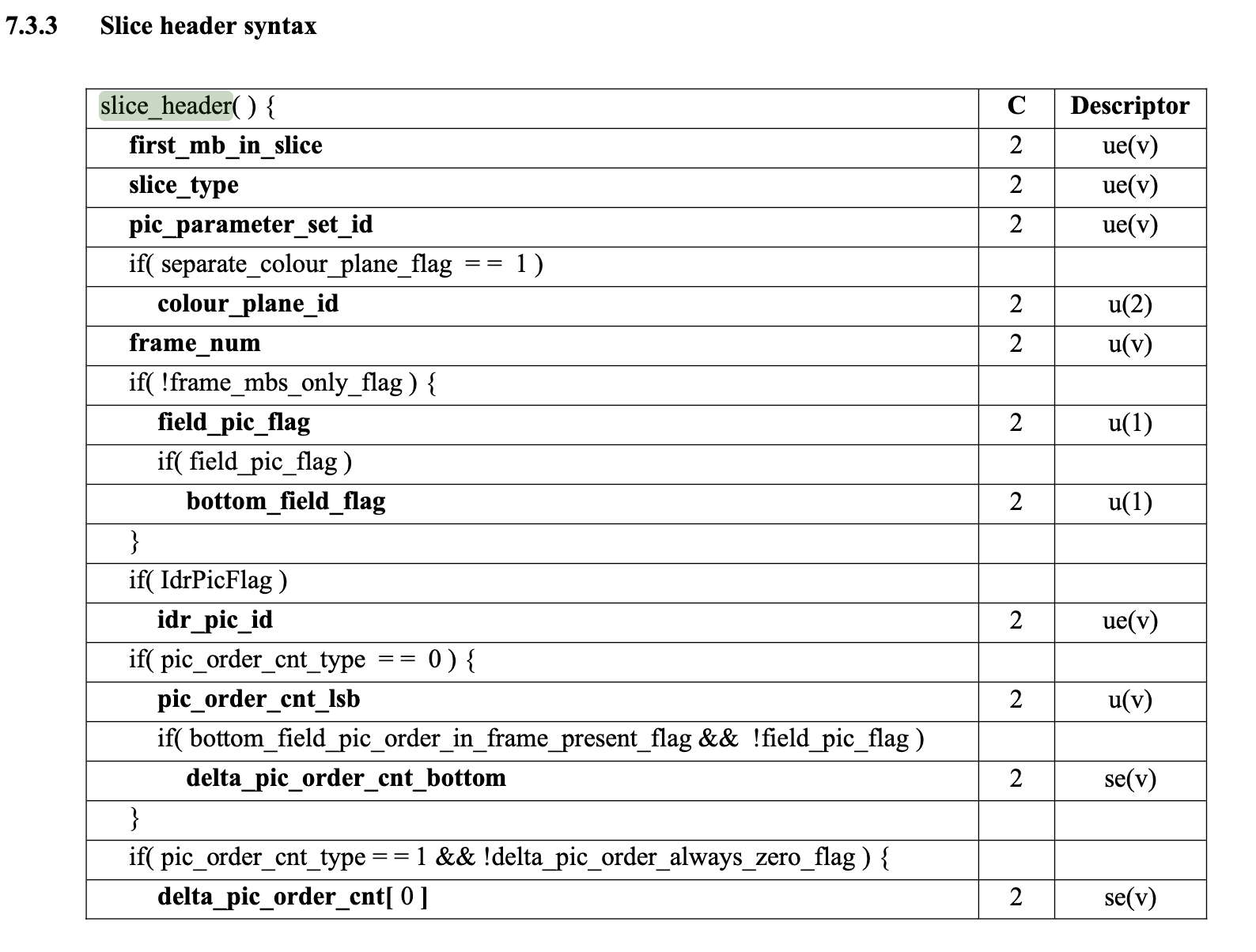
找到slice_layer_without_partitioning_rbsp()
找到slice_header()
ue(v)就是我们前面提到的无符号指数哥伦布编码 。
来看看如何使用无符号指数哥伦布进行编码:
先把要编码的数字加 1,假设我们要编码的数字是 4,那么我们先对 4 加 1,就是 5。
将加 1 后的数字 5 先转换成二进制,就是: 101。
转化成二进制之后,我们看转化成的二进制有多少位,然后在前面补位数减一个 0 。例如,101 有 3 位,那么我们应该在前面补两个 0。
最后,4 进行无符号指数哥伦布编码之后得到的二进制码流就是 0 0 1 0 1。
而前面的first_mb_in_slice表示该slice的第一个宏块在图像中的位置,涉及到一些更深入的知识,但是这里不用关心,因为我们的情况中first_mb_in_slice始终为0。
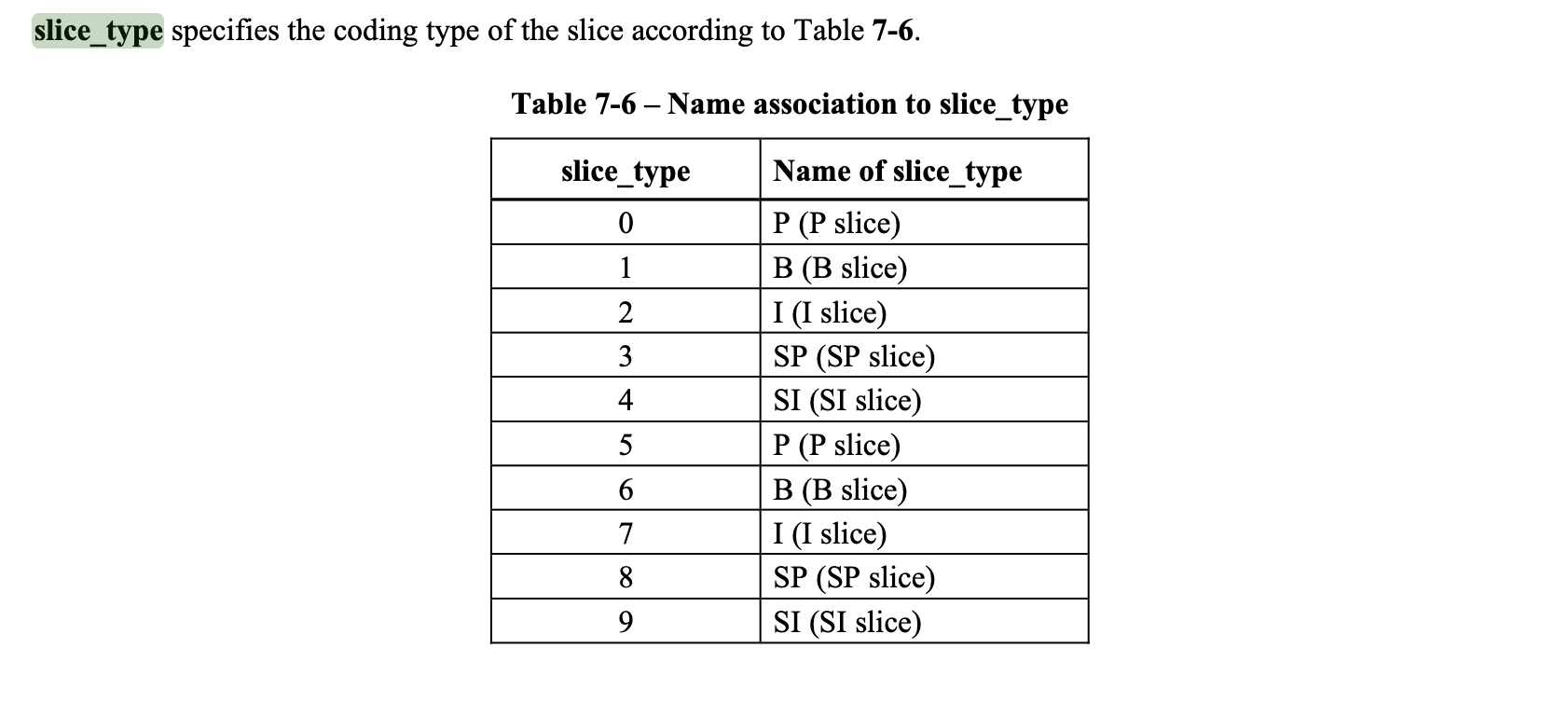
slice_type就是我们的帧类型,同样在7.4节给出了不同类型对应的值。
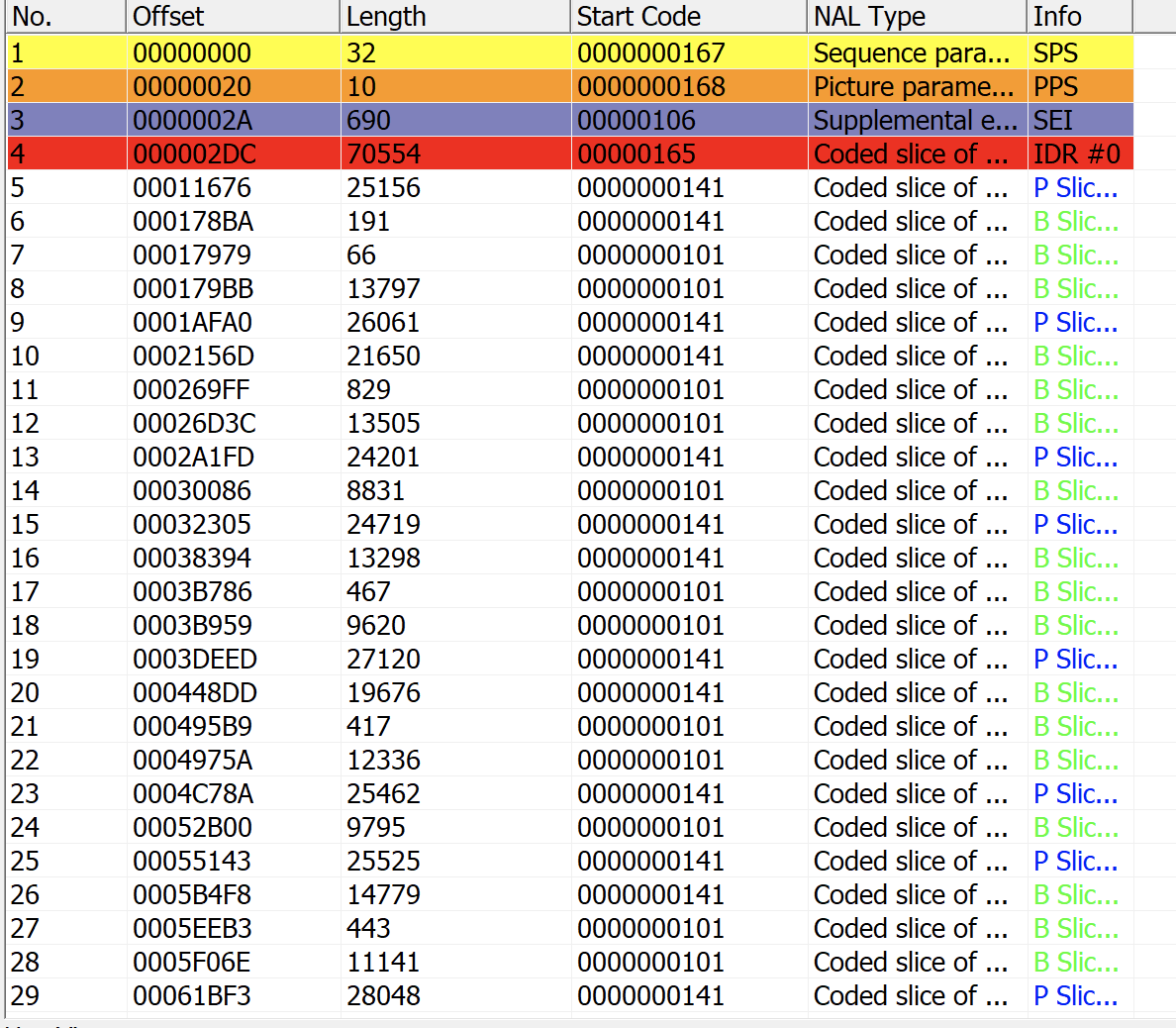
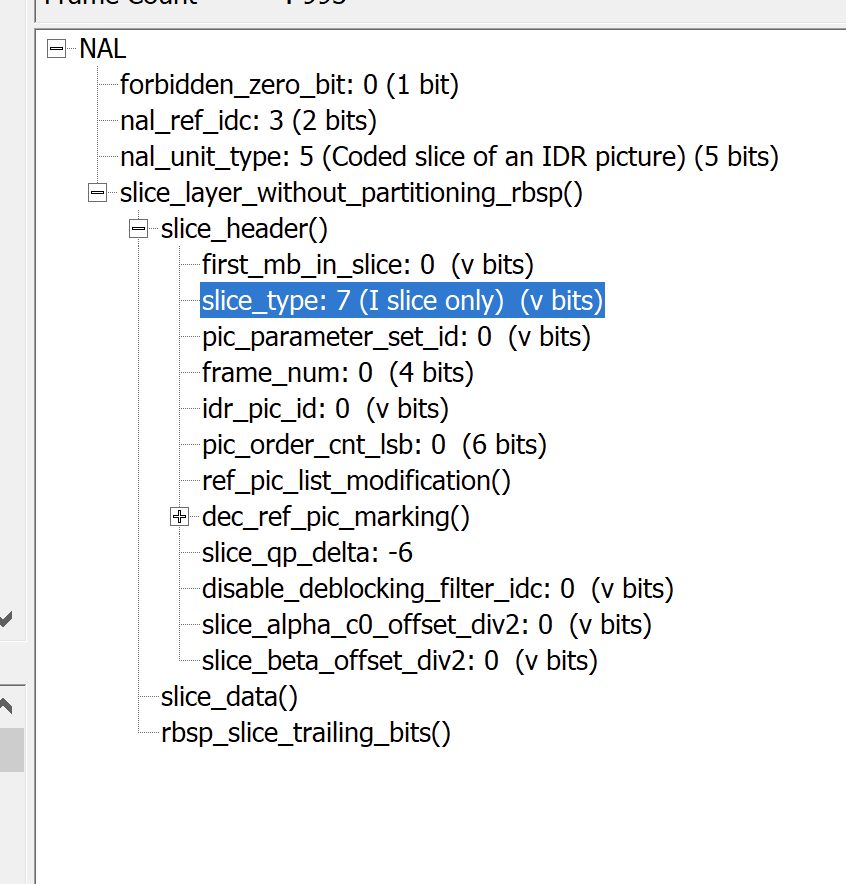
观察我们正常的h264裸流,这个slice_type的值都是被设置为7。
所以从RBSP的第一个字节开始,0的无符号指数哥伦布熵编码是0b1,7的无符号指数哥伦布熵编码是0b0001000,比特流应当是
找一个IDR帧的数据来验证一下
1 00 00 01 65 88 84 00 6F F9 C3 AB 0F 3B E0 BC 1E 03 54 39 CD 48 64 95 22 F4 6E AA 45 2F E6 8A 4F A2 1D 61 88 5C B2 0F 61 41 11 81 69 27 E5 93 DE D3 15 0D A2 97 F7 9A 41 E7 DF D5 B0 BD 50 57 D9 30 65 42 D9
RBSP为
88恰好对应0b10001000
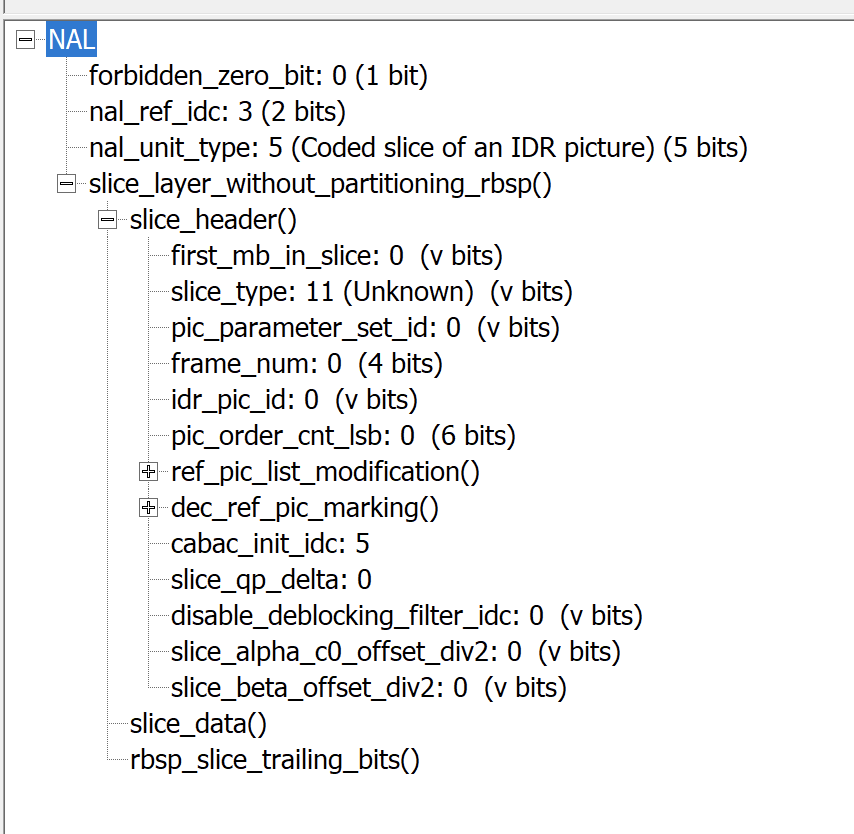
所以我直接对这个字节byte | 0x4,让这个字节变成0b10001100,于是slice_type就变成了11。这里主要是为了好处理数据,所以直接用二进制运算,实际上slice_type想改多少都可以。
修改后IDR的信息如下
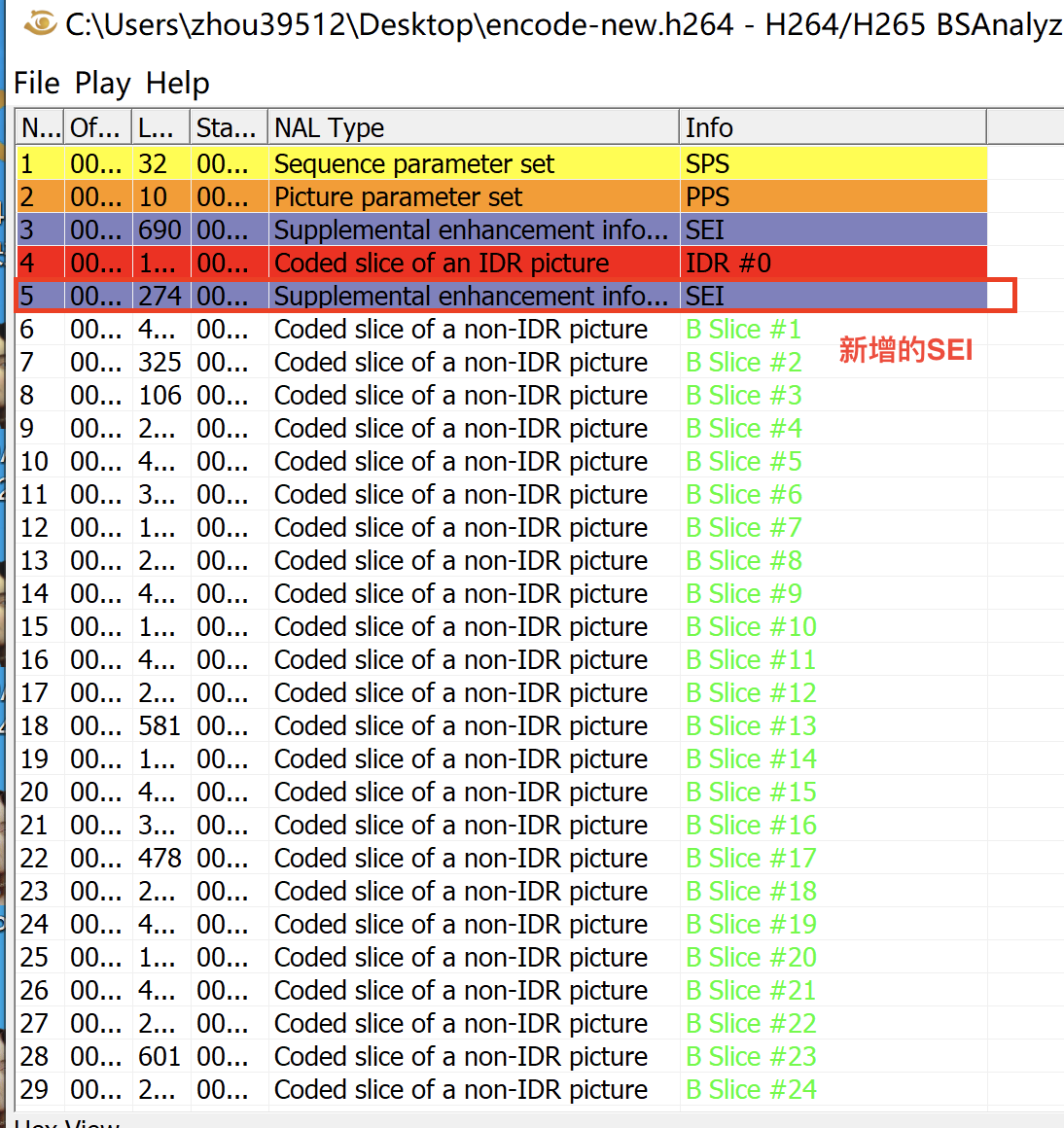
6.2 修改其他帧类型 关于其他帧类型的修改,题目是将所有帧类型都改为B帧,然后记录下原来的帧类型,存放在每个IDR帧之后的SEI帧里,供后续修复。
1 2 3 4 5 if nal_unit_type == 1 : slice_type = extract_slice_type(nalu_body) origin_slice_type_list.append(SLICE_TYPES[slice_type % 5 ]) print (SLICE_TYPES[slice_type % 5 ], end=' ' ) origin_data[start + 1 ] = origin_data[start + 1 ] | 0x4
效果如下
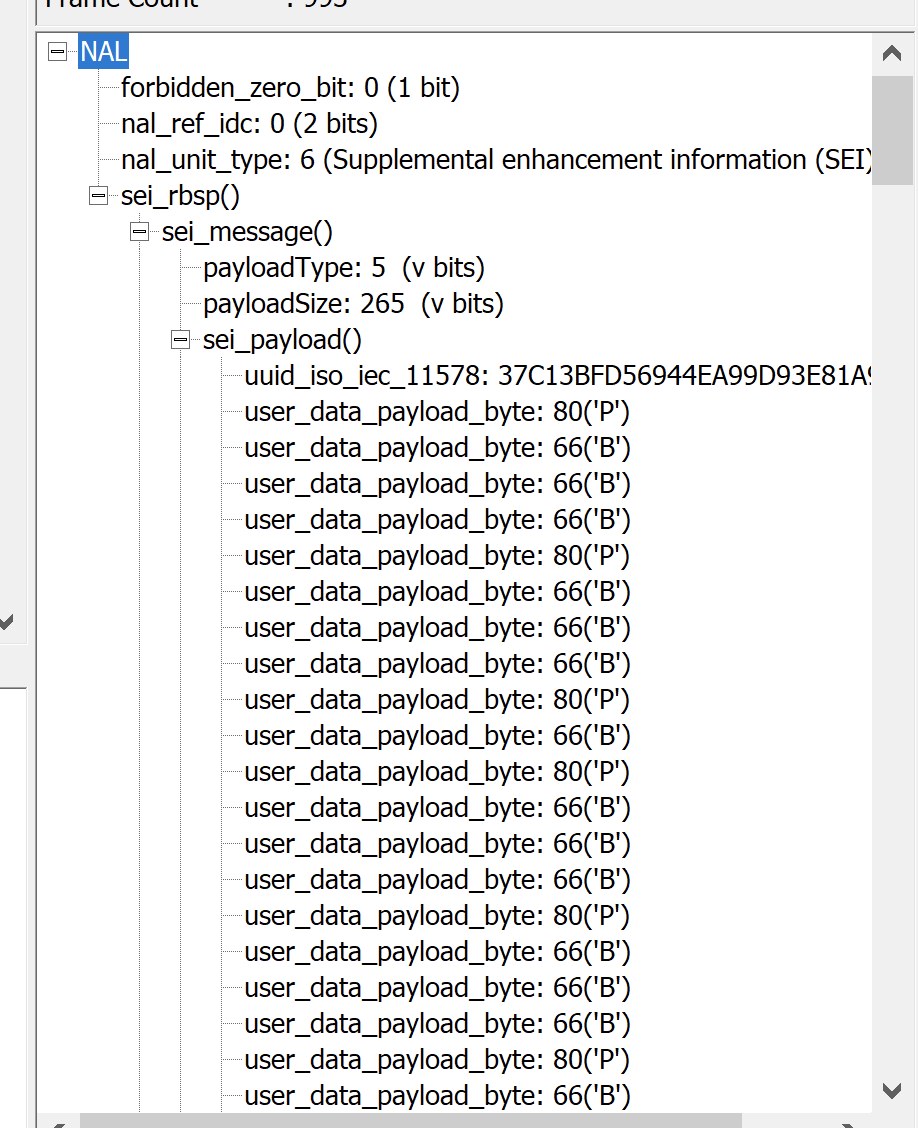
SEI内容
6.3 重新封装 由于ffmpeg的转换会重新编码,所以还是一样要加上-vcodec copy参数,使其不重新编码,而是只做封装。
1 2 os.system(f"ffmpeg -i {OUTPUT_H264} -vcodec copy {OUTPUT_MP4} " )
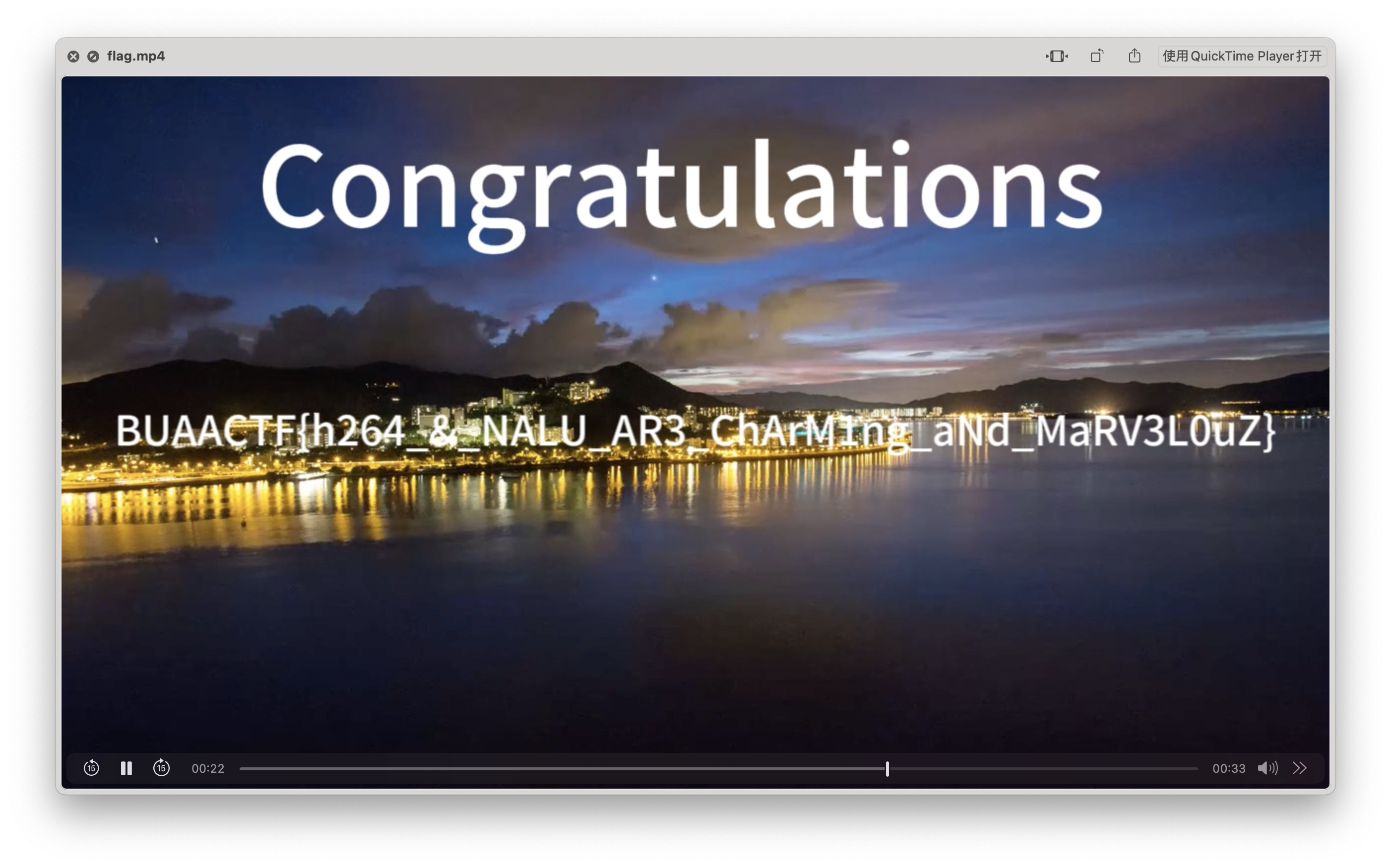
最后的视频成了这样
放出完整的出题脚本,只需要修改FLAG_VIDEO就可以生成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 import osfrom h26x_extractor.h26x_parser import H26xParserfrom uuid import uuid4SLICE_TYPES = {0 : 'P' , 1 : 'B' , 2 : 'I' , 3 : 'SP' , 4 : 'SI' } FLAG_VIDEO = 'flag.mp4' ORIGIN_H264='encode-origin.h264' OUTPUT_H264='encode-new.h264' OUTPUT_MP4='encode-output.mp4' OUTPUT_FLV='encode-output.flv' class BitStream : def __init__ (self, buf ): self .buffer = buf self .bit_pos = 0 self .byte_pos = 0 def ue (self ): count = 0 while self .u(1 ) == 0 : count += 1 res = ((1 << count) | self .u(count)) - 1 return res def u1 (self ): self .bit_pos += 1 res = self .buffer[self .byte_pos] >> (8 - self .bit_pos) & 0x01 if self .bit_pos == 8 : self .byte_pos += 1 self .bit_pos = 0 return res def u (self, n: int ): res = 0 for i in range (n): res <<= 1 res |= self .u1() return res def extract_slice_type (nalu_body ): body = BitStream(nalu_body) first_mb_in_slice = body.ue() slice_type = body.ue() return slice_type def generate_sequence_data (origin_slice_type_list: list ): sei_data = b'\x00\x00\x01\x06\x05' sei_payload_len = len (origin_slice_type_list) + 16 uuid = uuid4().bytes while sei_payload_len > 255 : sei_payload_len -= 255 sei_data += b'\xFF' sei_payload = uuid + '' .join(origin_slice_type_list).encode() sei_data += int .to_bytes(sei_payload_len, 1 , 'big' ) sei_data += sei_payload sei_data += b'\x80' return sei_data if __name__ == '__main__' : os.system(f'ffmpeg -i {FLAG_VIDEO} -c:v libx264 -crf 18 -preset medium -c:a aac -b:a 128k {ORIGIN_H264} ' ) f = open (ORIGIN_H264, 'rb' ) origin_data = list (f.read()) f.close() H26xParser = H26xParser(ORIGIN_H264, verbose=False ) H26xParser.parse() nalu_list = H26xParser.nalu_pos print (nalu_list) data = H26xParser.byte_stream origin_slice_type_list = [] sei_data_list = [] for tu in nalu_list: start, end, _, _, _, _ = tu rbsp = bytes (H26xParser.getRSBP(start, end)) nalu_header = rbsp[0 ] nal_unit_type = nalu_header & 0x1F nalu_body = rbsp[1 :] if nal_unit_type == 1 : slice_type = extract_slice_type(nalu_body) origin_slice_type_list.append(SLICE_TYPES[slice_type % 5 ]) print (SLICE_TYPES[slice_type % 5 ], end=' ' ) origin_data[start + 1 ] = origin_data[start + 1 ] | 0x4 elif nal_unit_type == 5 : origin_data[start + 1 ] = origin_data[start + 1 ] | 0x4 elif nal_unit_type == 7 and origin_slice_type_list: sei_data_list.append(generate_sequence_data(origin_slice_type_list)) origin_slice_type_list = [] sei_data_list.append(generate_sequence_data(origin_slice_type_list)) origin_slice_type_list = [] new_data = b'' start_pos = 0 count = 0 for start, end, _, _, _, _ in nalu_list: rbsp = bytes (H26xParser.getRSBP(start, end)) nalu_header = rbsp[0 ] nal_unit_type = nalu_header & 0x1F if nal_unit_type == 5 : new_data += bytes (origin_data[start_pos:end]) + sei_data_list[count] count += 1 start_pos = end new_data += bytes (origin_data[start_pos:]) f = open (OUTPUT_H264, 'wb' ) f.write(bytes (new_data)) f.close() os.system(f"ffmpeg -i {OUTPUT_H264} -vcodec copy {OUTPUT_MP4} " ) os.system(f"ffmpeg -i {OUTPUT_MP4} -vcodec copy {OUTPUT_FLV} " )
6.4 修复 理解了出题思路,解题就比较简单。将EXTRACT_VIDEO修改为损坏的视频即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 import osfrom h26x_extractor.h26x_parser import H26xParserfrom uuid import uuid4SLICE_TYPES = {0 : 'P' , 1 : 'B' , 2 : 'I' , 3 : 'SP' , 4 : 'SI' } EXTRACT_VIDEO = 'final/extract.flv' ORIGIN_H264 = 'decode-extract.h264' OUTPUT_H264 = 'decode-origin.h264' OUTPUT_MP4 = 'decode-origin.mp4' class BitStream : def __init__ (self, buf ): self .buffer = buf self .bit_pos = 0 self .byte_pos = 0 def ue (self ): count = 0 while self .u(1 ) == 0 : count += 1 res = ((1 << count) | self .u(count)) - 1 return res def u1 (self ): self .bit_pos += 1 res = self .buffer[self .byte_pos] >> (8 - self .bit_pos) & 0x01 if self .bit_pos == 8 : self .byte_pos += 1 self .bit_pos = 0 return res def u (self, n: int ): res = 0 for i in range (n): res <<= 1 res |= self .u1() return res def extract_slice_type (nalu_body ): body = BitStream(nalu_body) first_mb_in_slice = body.ue() slice_type = body.ue() return slice_type def read_sei (nalu_body ): payload_type = nalu_body[0 ] payload_size = 0 i = 1 while nalu_body[i] == 0xff : payload_size+=255 i+=1 payload_size += nalu_body[i] return [chr (i) for i in nalu_body[i+1 +16 :i+1 +payload_size]] if __name__ == '__main__' : os.system(f'ffmpeg -i {EXTRACT_VIDEO} -vcodec copy {ORIGIN_H264} ' ) f = open (ORIGIN_H264, 'rb' ) origin_data = list (f.read()) f.close() H26xParser = H26xParser(ORIGIN_H264, verbose=False ) H26xParser.parse() nalu_list = H26xParser.nalu_pos data = H26xParser.byte_stream origin_slice_type_list = [] prev_unit_type = 0 count=0 for tu in nalu_list: start, end, _, _, _, _ = tu rbsp = bytes (H26xParser.getRSBP(start, end)) nalu_header = rbsp[0 ] nal_unit_type = nalu_header & 0x1F nalu_body = rbsp[1 :] if nal_unit_type == 1 : if origin_slice_type_list[count]=='P' : origin_data[start + 1 ] = origin_data[start + 1 ] ^ 0x4 elif nal_unit_type == 5 : origin_data[start + 1 ] = origin_data[start + 1 ] ^ 0x4 elif nal_unit_type == 6 and prev_unit_type == 5 : count=0 print (read_sei(nalu_body)) origin_slice_type_list = read_sei(nalu_body) prev_unit_type = nal_unit_type new_data = bytes (origin_data) f = open (OUTPUT_H264, 'wb' ) f.write(bytes (new_data)) f.close() os.system(f"ffmpeg -i {OUTPUT_H264} -vcodec copy {OUTPUT_MP4} " )
7 总结 关于视频编码的隐写还有很多待发掘的地方,本文仅抛砖引玉,比如YUV像素信息就可以尝试LSB隐写。希望对你有些启发。
8 参考